
David Truchet, November 7, 2018
AEM comes standard with a functional search feature that can be leveraged when creating new AEM applications with no added cost. This solution is appropriate in many cases, mostly with simple sites that use search as a secondary feature. However, it can fall short in applications looking for an advanced search experience and features, or with huge repository sizes.
When you are dealing with a sizable amount of content and/or the file sizes you are storing are large, the AEM repository is consequently bigger and the out of the box solution starts showing its limitations. In those cases, offloading indexing and search out of the repository can be an excellent solution for the project.
Solr is one of the most powerful integrations with Adobe Experience Manager to improve indexing/search .
So what exactly is Solr? Solr is a popular, blazing-fast, open source enterprise search platform built on Apache Lucene. Solr is highly reliable, scalable, and fault tolerant. It provides distributed indexing, replication and load-balanced querying, automated fail-over and recovery, centralized configuration and much more. Solr also powers the search and navigation features of many of the world's largest internet sites.
In this article we are going to describe our experience working with AEM search and indexing (Oak). We're also going to explain how you can empower AEM search with Solr to create advanced search experiences and increase overall site performance.
AEM's Out of the Box Indexing and Search
Since version 6, the AEM platform is based on Apache Jackrabbit Oak. This is what AEM will use to work with indexes and search in the platform.
Oak based backend allows different indexers to be plugged into the repository, for example:
- Property Index: One of the most used by developers to be able to filter queries by specific properties. Index is stored in the repository itself.
- Lucene Index: This supports full-text indexing. Widely used on AEM projects and also stored as part of the AEM repository.
- Traversal Index: This is used if no other indexer is available. This means that the content is not indexed and content nodes are traversed to find matches to the query.
If multiple indexers are available for a query, each available indexer estimates the cost of executing the query. Oak then chooses the indexer with the lowest estimated cost.
Our experience with Oak -
While Oak indexing and searching is really powerful there are some cases in which we could face some challenges on AEM projects. Here is a list of cases that our clients faced while working with Oak:
- Number of indexed documents: due to a large number of indexed documents (2B documents Lucene limit), the repository size grows. This could cause performance issues on our publish environments.
- Size of indexed documents: Lucene indexes binaries and takes up a lot of space, this also causes the repository size to increase.
- Query caching strategy: there are some cases in which we are dealing with complex queries or we have a lot of traffic over the site and most of it is doing queries over AEM. On both cases we will need to perform caching to prevent overloading the servers. While caching is good, our client could request to always serve fresh content. Meaning that we can’t use the dispatcher or a CDN to cache our querie’s results.
- Mixed indexes: on searches for mixed content like assets, pages and products. If products are hosted on an external system, such as an e-commerce, in order to index them with Oak, you will need to import that content over the AEM repository. This requires a lot of work to maintain that update just to expose it over search.
Search features requested by our clients that are not covered by AEM Oak Lucene index:
- Natural Language search
- Keywords indexing
- Query elevation/Sponsored search
- Geospatial Search
- Query Suggestions and Spelling
If you are dealing with any of the above concerns or need to provide any of the features presented below on an AEM project, you might want to evaluate an integration with Apache Solr.
Why Solr?
The Solr platform is highly reliable, scalable and fault tolerant. It provides distributed indexing, replication and load-balanced querying, automated failover and recovery, and centralized configuration.
Solr provides a REST-like API. First, you put documents in it (called "indexing") via JSON, XML, CSV or binary over HTTP. Then you query it via HTTP GET and receive JSON, XML, CSV or binary results.
In addition to all the features the platform provides, you will also find:
- Advanced Full-Text Search Capabilities
- Optimized for High Volume Traffic
- Highly Scalable and Fault Tolerant
- Near Real-Time Indexing
- Faceted Search and Filtering
- Geospatial Search
- Highly Configurable and User Extensible Caching
- Query Suggestions, Spelling
- Rich Document Parsing
For more detail or a full list of features please visit the official Solr site.
Integrating AEM with Solr can deliver most of the search features that AEM Oak Lucene index can’t.
In addition, the scenarios presented in the previous section can be implemented successfully with Solr:
- Number/Size of indexed documents: Apache Solr includes the ability to set up a cluster of Solr servers that combines fault tolerance and high availability. This is called SolrCloud, these capabilities provide distributed indexing and search capabilities.
- Query caching strategy: avoids CDN or dispatcher cache and relies 100% on Solr search power to handle large amount of traffic. A multitude of smart caching options enable exacting control over repetitive results. This can help provide fresh content to your index and end-users.
- Mixed indexes: based on the REST API that Solr provides, any external system such as AEM or e-commerce can index and query over Solr. Meaning you can avoid porting external content to the AEM repository and just index the content directly over Solr.
There are two types of integrations you can do with AEM – we’ll cover those now.
1) Solr as an Oak index for AEM
This integration with Solr happens at AEM repository level and is one of the possible indexes that can be plugged into Oak.
The main purpose of the Solr as an Oak index is mainly full-text search but it can also be used to index search by path, property restrictions and primary type restrictions. As such, The Solr index in Oak can be used for any type of JCR query.
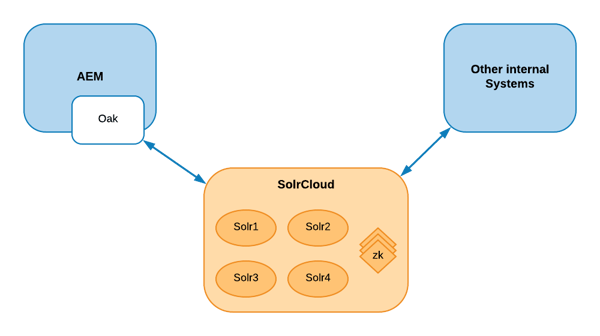
Index definition is hosted over nodes in the repository as the rest of the Oak indexes. The Oak Solr index creates one document in the Solr index for each node in the repository, each of these documents usually has at least a field for each property associated with the related node.
For Solr index to work with Oak, we need to setup a connection to able to communicate with a Solr instance/cluster. Apache Solr supports multiple deployment architectures, but the most common for production environments is SolrCloud cluster. This configuration happens also on the repository. For more information regarding how to setup indexes and configure Solr as an Oak index, you can review the official Oak Solr documentation.
To summarize: This integration happens quite fast, since you are plugged in as new indexer to Oak. This means you don’t need to worry about any custom code development and it will also allow developers to use plain JCR queries (transparent for developers).
However, there are some cases in which you might want to have more control over the queries and indexing that happens on the Solr side. For those scenarios this integration may not be the best fit.
2) Solr REST integration for AEM
Solr provides a REST-like API. In which, you index documents via JSON, XML, CSV or binary over HTTP. You can query it via HTTP GET and receive JSON, XML, CSV or binary results.
In order to integrate Solr REST API with AEM, you will need to develop JAVA code in your project bundle to be able to “talk” with the Solr API.
There are a couple of bootstrapping projects available online that can help you during development:
- AEM Solr Search
- AEM-Solr (Official Adobe sample)
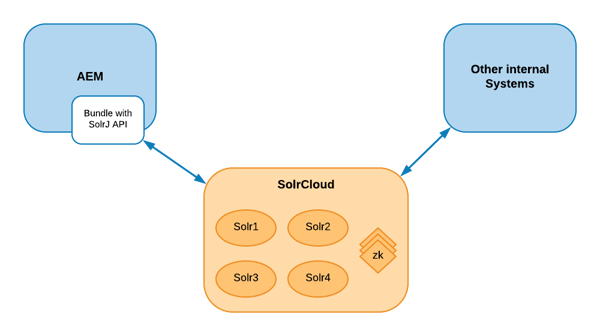
Both projects use SolrJ. This is an API that makes it easy for applications to talk to Solr. SolrJ hides a lot of the details of connecting to Solr and allows your application to interact with Solr with simple high-level methods. SolrJ supports most Solr APIs, and is highly configurable.
This method of Solr integration provides a few benefits that the Solr Oak indexing integration does not, such as:
- Full control over the Solr document model: developers have the ability to design the model that will be indexed in Solr. For example, if we want to index page in Solr the model could be composed with path, title, description, tags, keywords.
- Control over boosting specific fields in Solr document.
- Real time indexing is within your control: developers can trigger indexing request to Solr by any type of AEM events as create, delete, activation, deactivation.
- Comes handy when multiple heterogeneous systems are contributing for indexing.
The only real downside with this type of integration is the time/effort to implement it (which is higher than Solr Oak indexing integration). With that being said, this approach provides far more benefits.
Conclusion
After completing several projects working with each solution, we have found that both AEM Search and Solr Search have a place in AEM implementations, depending on the needs and the context.
The out-of-the-box AEM searching feature works well and is a good fit for small applications looking to reduce overall costs and simplify implementations. It requires no extra development time/effort to implement it. It can also be configured and optimized to overcome some of its limitations, albeit that would require some technical chops to accomplish.
On the other hand, integrating AEM with Solr requires design and development, as well as hosting and managing the Solr environments. This would increase costs and overall project timeline, but the reward is a wide variety of advanced searching features, blazing fast search performance, and a reduced footprint in AEM's environments.
If you can’t predict the amount of content that your AEM application will host or if you’re not sure you’ll need the advanced search features that Solr provides, it is always possible to start with the OOTB AEM Search and switch to Solr later down the road. An important consideration in this case is making sure that you implement all your search services using interfaces, so that you can later plug in Solr to enhance the searching experience easily. The same applies to projects already using AEM Search and facing performance problems, or if you’re not happy with the out of the box search features and limitations.
Want to know more?

Sources:
https://helpx.adobe.com/experience-manager/6-3/sites/deploying/using/queries-and-indexing.html
https://helpx.adobe.com/experience-manager/kt/eseminars/gems/Solr-as-an-Oak-index-for-AEM1.html
http://lucene.apache.org/solr/
https://helpx.adobe.com/experience-manager/using/aem_solr.html
Topics: Adobe Experience Manager, Developer Think Tank, Development